La vision par ordinateur, un domaine de l'informatique en pleine expansion, est devenue un atout majeur grâce à l'utilisation de réseaux neuronaux. Inspirés du cerveau humain, ils permettent aux machines d'interpréter et d'analyser à grande échelle des informations visuelles complexe. Cette avancée ouvre la voie à diverses applications, avec notamment la détection de surfaces spécifiques à partir de photographies aériennes ou d’images satellites : parking, toitures, décharges sauvages... Les applications sont sans limite. À L'Institut Paris Region, nous développons en interne des compétences en intelligence artificielle, en particulier dans le domaine du deep learning, dans le cadre de nos travaux de recherche et de développement d'applications innovantes. Dans ce premier numéro des chroniques de la data et de l’innovation, nous explorons la façon dont L'Institut Paris Region investit l’IA pour enrichir son système d’information géographique régional et alimenter les travaux de ses experts.
Au commencement, le potentiel solaire
L’énergie solaire constitue l’une des priorités et l’un des principaux leviers de développement des énergies renouvelables en Île-de-France.
En lien avec les objectifs de développement des énergies renouvelables, du zéro artificialisation nette (ZAN) et les obligations fixées par la loi relative à l’accélération de la production d’énergies renouvelables (loi APER – mars 2023), l’Institut a souhaité se doter de données sur les gisements solaires pour faciliter le développement de la filière en offrant une connaissance fine des gisements solaires disponibles.
Ainsi, après avoir modélisé les gisements solaires en toitures à partir de bases de données déjà existantes (via l’IGN notamment), l’institut a également modélisé les gisements solaires de parkings franciliens, à partir cette fois d’une base de données créée en interne et reposant sur un modèle d’intelligence artificielle de deep-learning.
Ce travail a permis de constituer une base de données des parkings franciliens selon une typologie détaillée, pour permettre ensuite des approfondissements adaptés par type d’acteurs (équipements publics, entreprises, habitat, logistique, etc.).
L’exemple de la détection des parkings sur les emprises logistiques
La logistique occupe une place cruciale en Île-de-France, avec une empreinte foncière considérable. Jusqu'à présent, les toitures et les parkings de ces zones étaient exclusivement dédiés à des besoins propres tels que l'exploitation des bâtiments, le stationnement des véhicules de fret et ceux des employés. Toutefois, les objectifs de transition écologique, notamment ZAN et ZEN, exigent désormais une diversification des fonctions de ces espaces urbanisés, une exigence qui se doit néanmoins de préserver les activités logistiques existantes.
Dans ce cadre, nos experts ont élaboré des modèles de détection par intelligence artificielle pour évaluer le potentiel solaire des parkings présents sur les espaces de la filière logistique francilienne. Cette approche novatrice a été réalisée en croisant des données géographiques avec des images aériennes, sur lesquelles des modèles d'apprentissage automatique ont permis d'identifier et de localiser avec précision les espaces de stationnement.
En quelques chiffres, cette méthode a permis d'identifier 127 parkings rattachés aux entrepôts logistiques pour une surface de 537 900 m². D'une manière plus globale, concernant les parkings rattachés aux activités économiques et industrielles , ce sont 1 780 parkings qui ont été identifiés, soit une surface de 8 899 375 m².
Cette méthodologie permet non seulement d'identifier des zones disponibles pour des projets d'énergies renouvelables, tels que des ombrières solaires, mais aussi d'optimiser l'utilisation d’espaces urbanisés. En effet, au-delà du développement des EnRR, ces repérages peuvent également aider à quantifier des zones à végétaliser dans le cadre de documents d'urbanisme locaux. Par exemple, en 2023, l’Institut a entrepris un travail ambitieux de recensement du nombre d'arbres sur l'ensemble des 12 000 km2 du territoire francilien. Quelque 26 millions d’arbres avaient ainsi été inventoriés par notre algorithme !
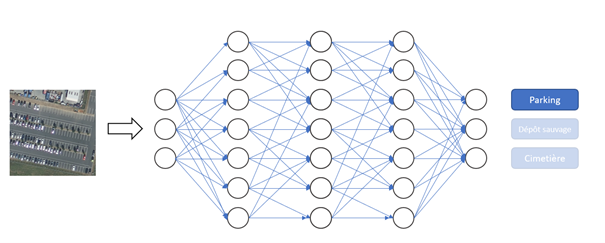
Comment l’IA arrive à géolocaliser des parkings ?
Dans le cas des parkings, pour parvenir à leur localisation et segmentation depuis des photographies aériennes, l'utilisation de l'intelligence artificielle s'avère être une approche prometteuse en exploitant des données variées sur différentes périodes (nous disposons de différentes campagnes entre 2008 à 2021) et en développant des modèles d'apprentissage automatique. Les images servent alors de base pour entrainer et tester notre modèle de reconnaissance. En complément, l'utilisation de couches géographiques, telles que celles fournies par OpenStreetMap (OSM), le mode d'occupation du sol (MOS) et celle du potentiel solaire des parkings de L'Institut Paris Region, permet un référencement précis des emplacements des parkings. Ces données géospatiales servent de guides pour l'annotation des images et l'entraînement du modèle. Dans un second temps, la phase de segmentation délimite les contours des emprises de parking sur les photographies aériennes afin d'obtenir un inventaire précis de l'emplacement de chaque parking sur l’ensemble du territoire régional.
Lors de ces étapes, l'IA intervient principalement dans le processus de localisation automatique. Les modèles de segmentation d'images, basés sur des réseaux de neurones convolutifs, permettent d’apprendre à identifier les caractéristiques distinctives des parkings à partir des données d'entraînement fournies. En utilisant ces modèles, il devient possible de scruter automatiquement l'ensemble du territoire régional pour localiser précisément les parkings comme cela est décrit ci-après.